Tacotron 무지성 구현 - 5/N
Decoder와 Post CBHG를 구현하다가 골머리 썩히고 왔습니다.
논문에서 Teacher Forcing을 사용하지 않은 줄 알았는데,
알고보니 사용했더라구요 :(

Teacher Forcing을 사용하려면 Reduction Factor의 배수에 맞게
Pre-processing 부분에서 알맞게 패딩을 해줘야하는데
저는 이 부분에 대해서 진행하지 않았기 때문에
많은 에러를 접하고 왔습니다.
따라서 앞서 작성한 포스팅에는 일부 수정해두었으니, 참고 바랍니다.
Hyper Parameters
Encoder 포스팅에서 다뤘던 Hyper Parameters와 차이점은
decoder_rnn_dim 하나밖에 없습니다.
각 모듈마다 많은 인자를 다루면
그만큼 복잡해질뿐더러, 하나의 인자를 변경했을 때
많은 부분을 수정해야합니다.
어떻게 보면 효율적이지만,
다르게 보면 의도한대로 잘 동작하지 않을 수 있으므로
유의해야할 것 같습니다.
import os
class Hparams():
# speaker name
speaker = 'KSS'
# Audio Pre-processing
origin_sample_rate = 44100
sample_rate = 22050
n_fft = 1024
hop_length = 256
win_length = 1024
n_mels = 80
reduction = 5
n_specs = n_fft // 2 + 1
fmin = 0
fmax = sample_rate // 2
min_level_db = -80
ref_level_db = 0
# Text Pre-processing
PAD = '_'
EOS = '~'
SPACE = ' '
SPECIAL = '.,!?'
JAMO_LEADS = "".join([chr(_) for _ in range(0x1100, 0x1113)])
JAMO_VOWELS = "".join([chr(_) for _ in range(0x1161, 0x1176)])
JAMO_TAILS = "".join([chr(_) for _ in range(0x11A8, 0x11C3)])
symbols = PAD + EOS + JAMO_LEADS + JAMO_VOWELS + JAMO_TAILS + SPACE + SPECIAL
_symbol_to_id = {s: i for i, s in enumerate(symbols)}
_id_to_symbol = {i: s for i, s in enumerate(symbols)}
# Pre-processing paths (text, mel, spec)
data_dir = os.path.join('data')
out_texts_dir = os.path.join(data_dir, 'texts')
out_mels_dir = os.path.join(data_dir, 'mels')
out_specs_dir = os.path.join(data_dir, 'specs')
# Embedding Layer
in_dim = 256
# Encoder Pre-net Layer
prenet_dropout_ratio = 0.5
prenet_linear_size = 256
# CBHG
cbhg_K = 16
cbhg_mp_k = 2
cbhg_mp_s = 1
cbhg_mp_p = 1
cbhg_mp_d = 2
cbhg_conv_proj_size = 128
cbhg_conv_proj_k = 3
cbhg_conv_proj_p = 1
cbhg_gru_hidden_dim = 128
# Decoder
decoder_rnn_dim = 256
Decoder
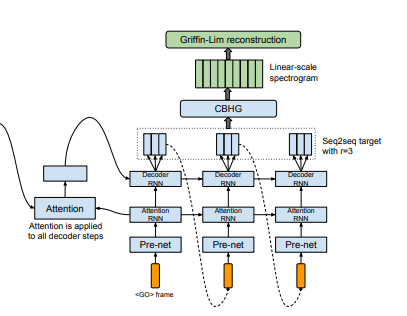
Decoder PreNet
첫 번째 Layer는 Attention이 아닌 Decoder PreNet입니다.
왜냐하면, Mel 하나의 Frame에 맞게 생성된 데이터는
Attention에 입력되기 전에
Decoder PreNet Layer와 AttentionRNN Layer를 지나가기 때문이죠.
앞서 작성했던 포스팅에서 PreNet을 다뤘을 때
인자 중 user_decoder=False를 작성했던 것을 보셨을겁니다.
이번 Decoder에 사용되는 PreNet은 use_decoder 인자를
True로 바꿔서 사용하게 됩니다.
큰 차이점은 없고,
use_decoder=True로 사용 시 self.prenet_input_dim shape가
self.Hparams.n_mels*self.Hparams.reduction으로 변경됩니다.
왜냐하면, 논문에서는 Reduction Factor를 사용해서
Mel Frame을 Reduction Factor 배수만큼 생성했을 때
그만큼 효과를 보았다고 기재해두었기 때문에
저 또한 논문에 맞게 Input shape을 수정했습니다.

class PreNet(torch.nn.Module):
def __init__(self, Hparams, use_decoder=False):
super(PreNet, self).__init__()
self.Hparams = Hparams
self.prenet_input_dim = self.Hparams.in_dim
if use_decoder==True:
self.prenet_input_dim = self.Hparams.n_mels*self.Hparams.reduction
in_sizes = [self.prenet_input_dim] + [self.Hparams.prenet_linear_size]
out_sizes = [self.Hparams.prenet_linear_size] + [self.Hparams.prenet_linear_size//2]
layers = []
for (in_features, out_features) in zip(in_sizes, out_sizes):
layers += [CustomLinear(in_features=in_features,
out_features=out_features,
activation='relu',
dropout=self.Hparams.prenet_dropout_ratio)]
self.prenet = torch.nn.Sequential(*layers)
def forward(self, x):
return self.prenet(x)
앞서 언급했듯이 Decoder PreNet의 첫 번째 Input은
Mel이 아닌 Mel의 첫 번째 Frame에 맞는 dim을 가진 데이터입니다.

이게 무슨 말이냐면,
Teacher Forcing의 입력값을 제외하고
Text와 Mel Lengths이 전부일텐데,
Text는 Encoder 입력값이고,
Mel Lengths는 Decoder가 생성하는 Frame의 Length의 기준을
잡아주는 역할을 하는 것일 뿐입니다.
그리고 Attention에서 나온 출력값은
DecoderRNN과 AttentionRNN에서 나온 값과 계산되어 Frame을 생성합니다.
그러면 도대체 Decoder는 처음에 어떤 것을 입력을 받고 Frame생성을 시작할까요?
위의 그림에 그려져있는 화살표를 보면
첫 번째 화살표에 <GO> frame이라고 명시 되어 있는 부분이
처음 Decoder에 입력되는 입력값입니다.
아래의 이미지에서 볼 수 있듯이,
<GO> Frame은 zero-frame으로 생성되며
매 step 마다 Decoder의 첫 입력 값으로 사용됩니다.


Decoder 구현 시 Teacher Forcing에 대한 사용 여부와
Teacher Forcing을 사용할 때
Input을 zero-frame과 Ground Truth간에 서로 바꾸게끔 하는
기능을 잘 구현해야 할 것 같습니다.
Decoder PreNet의 첫 입력은 <GO> frame에 해당하는 부분이므로
아래의 코드 블럭과 같이 변수를 지정합니다.
init_dec_prenet_input = encoded.data.new(B, hparams.n_mels*hparams.reduction).zero_()
Decoder PreNet에 init_dec_prenet_input을 입력하고 출력해봅니다.
dataset = KSSDataset(hparams)
dataloader = torch.utils.data.DataLoader(dataset,
batch_size=4,
shuffle=True,
collate_fn=collate_fn)
encoder = Encoder(hparams, use_decoder=False, use_post=False)
encoded = encoder(texts)
B = texts.size(0)
init_dec_prenet_input = encoded.data.new(B, hparams.n_mels*hparams.reduction).zero_()
dec_prenet = PreNet(hparams, use_decoder=True)
for step, values in enumerate(dataloader):
_, _, _, _ = values
dec_prenet_result = dec_prenet(init_dec_prenet_input)
print('Decoder PreNet result: {} \n'.format(
dec_prenet_result.size()))
if step == 0:
break
####
Decoder PreNet result: torch.Size([4, 128])dec_prenet = PreNet(hparams, use_decoder=True)
print(dec_prenet)
####
PreNet(
(prenet): Sequential(
(0): CustomLinear(
(linear): Linear(in_features=400, out_features=256, bias=True)
(activation): ReLU()
(dropout): Dropout(p=0.5, inplace=False)
)
(1): CustomLinear(
(linear): Linear(in_features=256, out_features=128, bias=True)
(activation): ReLU()
(dropout): Dropout(p=0.5, inplace=False)
)
)
)
AttentionRNN
Decoder PreNet 다음은 AttentionRNN Layer 입니다.
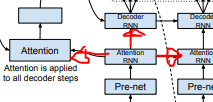
AttentionRNN Layer는 위의 이미지에서 볼 수 있다시피,
Attention Layer에 출력을 전달합니다.
그리고 DecoderRNN과 그 다음 AttentionRNN에
각각의 현재 Output과 Hidden state를 그 다음 Layer에 전달합니다.
다시 말하면,
처음 frame 생성을 시작하는 AttentionRNN도,
DecoderRNN도
각자 입력받는 전 단계의 Output과 Hidden state가 있다는 말입니다.
아래 두 번째 코드 블럭을 보시면,
init_attn_rnn_state가 zero값으로
Input shape에 맞게 지정되어있는 것을 볼 수 있습니다.
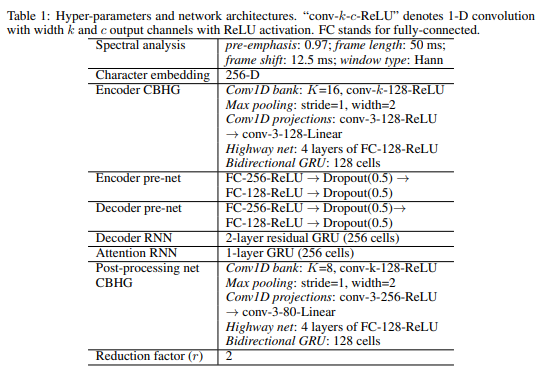
다만, Table 1에서 볼 수 있듯이
1-layer GRU (256cells) 라고 기재되어있으므로
그에 상응하게끔 torch.nn.GRU()의 hidden_size 인자 값을
알맞게 입력해줍니다.

class AttentionRNN(torch.nn.Module):
def __init__(self, Hparams):
super(AttentionRNN, self).__init__()
self.Hparams = Hparams
self.attention_rnn = torch.nn.GRU(input_size=self.Hparams.prenet_linear_size//2, # 128
hidden_size=self.Hparams.cbhg_gru_hidden_dim*2, # 256
num_layers=1,
batch_first=True,
bidirectional=False)
def forward(self, x, h):
# Add and Convert Time axis
# (B, Attn_dim) -> (B, Attn_dim, 1) -> (B, 1, Attn_dim)
x = x.unsqueeze(-1).permute(0,2,1)
x, h = self.attention_rnn(x, h)
# h: attention 의 query 값으로 들어감
return x, h위 부분은 torch.nn.GRU() 모듈로 구성되어 있지만
실제로는 torch.nn.GRUCell() 모듈이 사용되어야합니다.
(추후에 수정 예정)
encoder = Encoder(hparams, use_decoder=False, use_post=False)
encoded = encoder(texts)
B = encoded.size(0)
init_attn_rnn_input = encoded.data.new(B, hparams.n_mels*hparams.reduction).zero_()
init_attn_rnn_state = encoded.data.new(1, B, hparams.cbhg_gru_hidden_dim*2).zero_()
dec_prenet = PreNet(hparams, use_decoder=True)
attention_rnn = AttentionRNN(hparams)
dec_prenet_result = dec_prenet(init_attn_rnn_input)
attention_rnn_result, current_attn_rnn_state = attention_rnn(dec_prenet_result,
init_attn_rnn_state)
print('Initial Decoder input: {} \nInitial Decoder Hidden sate: {} \n'.format(
init_dec_attn_rnn_input.size(),
init_dec_attn_rnn_state.size()))
print('Encoder result: {} \nDecoder PreNet result: {} \nAttentionRNN result: {} \nCurrent AttentionRNN h-state: {} \n'.format(
encoded.size(),
dec_prenet_result.size(),
attention_rnn_result.size(),
current_attn_rnn_state.size()))
####
Initial Decoder input: torch.Size([4, 400])
Initial Decoder Hidden sate: torch.Size([1, 4, 256])
Encoder result: torch.Size([4, 50, 256])
Decoder PreNet result: torch.Size([4, 128])
Decoder AttentionRNN result: torch.Size([4, 1, 256])
Current Hidden state: torch.Size([1, 4, 256])dec_attn_rnn = AttentionRNN(hparams)
print(dec_attn_rnn)
####
AttentionRNN(
(attention_rnn): GRU(128, 256, batch_first=True)
)
Attention & Attention Wrapper
Attention Layer 구현 관련된 부분은
"텐서플로2와 머신러닝으로 시작하는 자연어처리" 도서를 참고했습니다.
아래에 github 링크를 남겨둡니다.
https://github.com/NLP-kr/tensorflow-ml-nlp-tf2
GitHub - NLP-kr/tensorflow-ml-nlp-tf2: 텐서플로2와 머신러닝으로 시작하는 자연어처리 (로지스틱회귀부
텐서플로2와 머신러닝으로 시작하는 자연어처리 (로지스틱회귀부터 BERT와 GPT2까지) 실습자료 - GitHub - NLP-kr/tensorflow-ml-nlp-tf2: 텐서플로2와 머신러닝으로 시작하는 자연어처리 (로지스틱회귀부터
github.com
Attention Wrapper는 간단한 클래스로 구현했습니다.
구글링해봐도 계산과정이 각기 달라서
저는 그냥 더하는 것으로 했습니다.
코더가 되지 않기 위해 논문을 주로 보려고 노력하는데
이 부분은 조금 난해하네요.

Attention output인 Context Vector와
AttentionRNN cell output 값을 concatenate 했다고 하는데
이 부분 잘 아시는 분 있으시면 댓글 부탁드립니다.
# Attention
class BahdanauAttention(torch.nn.Module):
def __init__(self, Hparams):
super(BahdanauAttention, self).__init__()
self.Hparams = Hparams
self.W1 = CustomLinear(in_features=self.Hparams.cbhg_gru_hidden_dim*2,# 256
out_features=self.Hparams.cbhg_gru_hidden_dim, # 128
activation=None,
dropout=None) # values: encoder output (batch_size, num_timesteps, units)
self.W2 = CustomLinear(in_features=self.Hparams.cbhg_gru_hidden_dim*2,# 256
out_features=self.Hparams.cbhg_gru_hidden_dim, # 128
activation=None,
dropout=None) # query: decoder attention rnn hidden state (num, batch_size, units)
self.V = CustomLinear(in_features=self.Hparams.cbhg_gru_hidden_dim,
out_features=1,
activation=None,
dropout=None)
def forward(self, query, values):
# convert to time axis from num axis which is num of gru layers
query_with_time_axis = query.permute(1,0,2)
# scoring
score = self.V(torch.tanh(self.W1(values) + self.W2(query_with_time_axis)))
# softmax
# (batch_size, num_timesteps, self.V out_features)
alignment = torch.softmax(score, dim=1)
# calculating with attention
# transpose: (batch_size, cbhg_gru_hidden_dim, num_timesteps)
# matmul: (batch_size, cbhg_gru_hidden_dim, encoder_dim)
# reduce_sum: (64, 1024) (batch_size, cbhg_gru_hidden_dim)
# expand_dim: (batch_size, time_axis, encoder_dim)
context = torch.sum(torch.matmul(alignment.permute(0,2,1), values), dim=1).unsqueeze(1)
return context, alignment
# Attention Wrapper
class AttentionWrapper(torch.nn.Module):
def __init__(self):
super(AttentionWrapper, self).__init__()
def forward(self, context, attention_rnn_result): # values: attention values, key: decoder inputs
return context + attention_rnn_result
Attention Layer까지 고려한 출력은 아래와 같습니다.
encoder = Encoder(hparams, use_decoder=False, use_post=False)
encoded = encoder(texts)
B = encoded.size(0)
init_attn_rnn_input = encoded.data.new(B, hparams.n_mels*hparams.reduction).zero_()
init_attn_rnn_state = encoded.data.new(1, B, hparams.cbhg_gru_hidden_dim*2).zero_()
dec_prenet = PreNet(hparams, use_decoder=True)
attention_rnn = AttentionRNN(hparams)
attention = BahdanauAttention(hparams)
attention_wrapper = AttentionWrapper()
dec_prenet_result = dec_prenet(init_attn_rnn_input)
attention_rnn_result, current_attn_rnn_state = attention_rnn(dec_prenet_result,
init_attn_rnn_state)
context, alignment = attention(current_attn_rnn_state, encoded)
attention_result = attention_wrapper(context, attention_rnn_result)
print('Initial Decoder input: {} \nInitial Decoder Hidden sate: {} \n'.format(
init_dec_attn_rnn_input.size(),
init_dec_attn_rnn_state.size()))
print('Encoder result: {} \nDecoder PreNet result: {} \nAttentionRNN result: {} \nCurrent AttentionRNN h-state: {} \nContext Vector: {} \nAlignment: {} \nAttention result: {} \n'.format(
encoded.size(),
dec_prenet_result.size(),
attention_rnn_result.size(),
current_attn_rnn_state.size(),
context.size(),
alignment.size(),
attention_result.size()))
####
Initial Decoder input: torch.Size([4, 400])
Initial Decoder Hidden sate: torch.Size([1, 4, 256])
Encoder result: torch.Size([4, 50, 256])
Decoder PreNet result: torch.Size([4, 128])
AttentionRNN result: torch.Size([4, 1, 256])
Current AttentionRNN h-state: torch.Size([1, 4, 256])
Context Vector: torch.Size([4, 1, 256])
Alignment: torch.Size([4, 50, 1])
Attention result: torch.Size([4, 1, 256])
<Attention Layer & AttentionWrapper 수정>
# Attention
class BahdanauAttention(torch.nn.Module):
def __init__(self):
super(BahdanauAttention, self).__init__()
def forward(self, query, values):
if (query.size(0) != values.size(0)):
query_with_time_axis = query.permute(1,0,2)
elif (query.size(0) == values.size(0)):
query_with_time_axis = query
score = torch.matmul(query_with_time_axis, values.permute(0,2,1))
alignment = torch.softmax(score.permute(0,2,1), dim=1)
context = torch.matmul(alignment.permute(0,2,1), values)
return context, alignment
# Attention Wrapper
class AttentionWrapper(torch.nn.Module):
def __init__(self):
super(AttentionWrapper, self).__init__()
def forward(self, context, query):
return torch.cat((context, query), dim=-1)encoder = Encoder(hparams)
encoded = encoder(texts)
B = encoded.size(0)
init_attn_rnn_input = encoded.data.new(B, hparams.n_mels*hparams.reduction).zero_()
init_attn_rnn_state = encoded.data.new(1, B, hparams.cbhg_gru_hidden_dim*2).zero_()
dec_prenet = PreNet(hparams, use_decoder=True)
attention_rnn = AttentionRNN(hparams)
attention = BahdanauAttention()
attention_wrapper = AttentionWrapper()
dec_prenet_result = dec_prenet(init_attn_rnn_input)
attention_rnn_result, current_attn_rnn_state = attention_rnn(dec_prenet_result,
init_attn_rnn_state)
# context, alignment = attention(current_attn_rnn_state, encoded)
context, alignment = attention(attention_rnn_result, encoded)
attention_result = attention_wrapper(context, attention_rnn_result)
print('Initial Decoder input: {} \nInitial Decoder Hidden sate: {} \n'.format(
init_attn_rnn_input.size(),
init_attn_rnn_state.size()))
print('Encoder result: {} \nDecoder PreNet result: {} \nAttentionRNN result: {} \nCurrent AttentionRNN h-state: {} \nContext Vector: {} \nAlignment: {} \nAttention result: {} \n'.format(
encoded.size(),
dec_prenet_result.size(),
attention_rnn_result.size(),
current_attn_rnn_state.size(),
context.size(),
alignment.size(),
attention_result.size()))
####
Initial Decoder input: torch.Size([4, 400])
Initial Decoder Hidden sate: torch.Size([1, 4, 256])
Encoder result: torch.Size([4, 50, 256])
Decoder PreNet result: torch.Size([4, 128])
AttentionRNN result: torch.Size([4, 1, 256])
Current AttentionRNN h-state: torch.Size([1, 4, 256])
Context Vector: torch.Size([4, 1, 256])
Alignment: torch.Size([4, 50, 1])
Attention result: torch.Size([4, 1, 512])DecoderRNN
DecoderRNN에서 Residual Connection을 진행했다고 합니다.
따라서 저는 이전 Encoder CBHG 구현할 때 사용했던 방법을
그대로 채택하겠습니다.
-> Residual Connection은 Decoder에서 직접 진행

class DecoderRNN(torch.nn.Module):
def __init__(self, Hparams):
super(DecoderRNN, self).__init__()
self.Hparams = Hparams
self.residual = torch.nn.Identity()
self.decoder_rnn = torch.nn.GRU(input_size=self.Hparams.cbhg_gru_hidden_dim*2,
hidden_size=self.Hparams.decoder_rnn_dim,
num_layers=2,
batch_first=True,
bidirectional=False)
def forward(self, x, h):
short_cut = self.residual(x)
x, h = self.decoder_rnn(x, h)
x = x + short_cut
return x, h
위 코드에서 torch.nn.GRU() 모듈이 사용되었지만,
실제로는 torch.nn.GRUCell() 모듈이 사용되어야 합니다.
(추후에 수정 예정)
DecoderRNN까지 고려한 출력은 아래와 같습니다.
encoder = Encoder(hparams, use_decoder=False, use_post=False)
encoded = encoder(texts)
B = encoded.size(0)
init_attn_rnn_input = encoded.data.new(B, hparams.n_mels*hparams.reduction).zero_()
init_attn_rnn_state = encoded.data.new(1, B, hparams.cbhg_gru_hidden_dim*2).zero_()
init_dec_rnn_state = encoded.data.new(2, B, hparams.cbhg_gru_hidden_dim*2).zero_()
dec_prenet = PreNet(hparams, use_decoder=True)
attention_rnn = AttentionRNN(hparams)
attention = BahdanauAttention(hparams)
attention_wrapper = AttentionWrapper()
decoder_rnn = DecoderRNN(hparams)
dec_prenet_result = dec_prenet(init_attn_rnn_input)
attention_rnn_result, current_attn_rnn_state = attention_rnn(dec_prenet_result,
init_attn_rnn_state)
context, alignment = attention(current_attn_rnn_state, encoded)
attention_result = attention_wrapper(context, attention_rnn_result)
dec_rnn_result, current_dec_rnn_state = decoder_rnn(attention_result,
init_dec_decoder_rnn_state)
print('Initial Decoder input: {} \nInitial Decoder Hidden sate: {} \n'.format(
init_dec_attn_rnn_input.size(),
init_dec_attn_rnn_state.size()))
print('Encoder result: {} \nDecoder PreNet result: {} \nAttentionRNN result: {}\
\nCurrent AttentionRNN h-state: {} \nCurrent DecoderRNN h-state: {} \nContext Vector: {}\
\nAlignment: {} \nAttention result: {} \nDecoderRNN result: {} \n'.format(
encoded.size(),
dec_prenet_result.size(),
attention_rnn_result.size(),
current_attn_rnn_state.size(),
current_dec_rnn_state.size(),
context.size(),
alignment.size(),
attention_result.size(),
dec_rnn_result.size()))
####
Initial Decoder input: torch.Size([4, 400])
Initial Decoder Hidden sate: torch.Size([1, 4, 256])
Encoder result: torch.Size([4, 50, 256])
Decoder PreNet result: torch.Size([4, 128])
AttentionRNN result: torch.Size([4, 1, 256])
Current AttentionRNN h-state: torch.Size([1, 4, 256])
Current DecoderRNN h-state: torch.Size([2, 4, 256])
Context Vector: torch.Size([4, 1, 256])
Alignment: torch.Size([4, 50, 1])
Attention result: torch.Size([4, 1, 256])
DecoderRNN result: torch.Size([4, 1, 256])decoder_rnn = DecoderRNN(hparams)
print(decoder_rnn)
####
DecoderRNN(
(residual): Identity()
(decoder_rnn): GRU(256, 256, num_layers=2, batch_first=True)
)
Decoder
대망의 Decoder 입니다.
한번에 머릿속에서 짜잔 하고
지식이 쏟아져 내려왔으면 좋겠지만,
저는 많은 시행착오 끝에 어찌저찌 구현은 했습니다.
그래도 Attention 부분에서 조금 확실하지 않은 부분이 있어서
완벽한 답안은 아닌 것 같습니다.
그래도 Input Ouput shape은 의도한대로 됐으니
일단 진행하겠습니다.
앞서 써내려왔던 것 중에 못 보던 글자들이 있습니다.
__init__ 부분에 있는 teacher_forcing=True 인자를 지정한 것과
self.proj_to_mel Layer를 정의한 부분이 조금 다르네요.
teacher_forcing=True 인자는 말 그대로
teacher_forcing을 할지 말지 결정하는 인자이면서
입력이 잘못 들어왔을 때를 대비한 인자이기도 합니다.
teacher_forcing=True로 지정하고, ground_truth를 입력하지 않아도
기존 모델 구조에 따른 방식을 채택하게끔 했습니다.
그 반대로 해도 기본 구조를 따르고,
무조건 teacher_forcing과 ground_truth에 대한 입력을 해주어야
Teacher Forcing이 진행됩니다.
self.proj_to_mel Layer는
Post CBHG에 입력되기 전 단계의 Layer라고 보시면 될 것 같습니다.
다만 유의할 점은 Output shape가
self.Haprams.n_mels*self.Hparams.reduction
이라는 부분을 잘 보시면 좋을 듯 합니다.
forward 부분을 보면
encoded(Encoder Output)와
mel_lengths(T값을 결정하는데 사용됨)
ground_truth(True Mel)이 있습니다.
그리고 if 문이 바로 이어지는데
Teacher Forcing 사용 시
Ground Truth의 shape을 손보기 위한 부분입니다.
shape을 (T, B, n_mels*reduction)으로 변경하는데,
T값은 전체 프레임에 해당하는 부분이므로
프레임 하나하나를 편리하게 Ground Truth로
이용하기 위함이라고 보면됩니다.
해당 if 문에서 조건에 해당하는 부분은 그 밑에도 이어집니다.
(하나만 사용하고 싶었는데
뭔가 번뜩 떠오르는 아이디어가 없었네요.)
class Decoder(torch.nn.Module):
def __init__(self, Hparams, use_decoder=True, teacher_forcing=True):
super(Decoder, self).__init__()
self.Hparams = Hparams
self.use_decoder=use_decoder
self.teacher_forcing=teacher_forcing
self.dec_prenet = PreNet(Hparams, use_decoder=self.use_decoder)
self.attention_rnn = AttentionRNN(self.Hparams)
self.attention = BahdanauAttention()
self.attention_wrapper = AttentionWrapper()
self.pre_decoder_rnn = CustomLinear(in_features=self.Hparams.cbhg_gru_hidden_dim*4,
out_features=self.Hparams.decoder_rnn_dim,
activation=None,
dropout=None)
self.residual = torch.nn.Identity()
self.decoder_rnn = DecoderRNN(self.Hparams)
self.proj_to_mel = CustomLinear(in_features=self.Hparams.decoder_rnn_dim,
out_features=self.Hparams.n_mels*self.Hparams.reduction,
activation=None,
dropout=None)
def forward(self, encoded, mel_lengths, ground_truth=None):
B = encoded.size(0)
T = torch.max(mel_lengths) // self.Hparams.reduction
if (self.teacher_forcing == True and ground_truth != None):
decoder_in = ground_truth.view(B,-1,self.Hparams.n_mels*self.Hparams.reduction)
decoder_in = decoder_in.permute(1,0,2) # (B, T, n_mels) -> (T, B, n_mels)
decoder_out_list = []
align_list = []
t = 0
while True:
if (t == 0):
# initial decoder input (B, n_mels*r)
current_dec_in = encoded.data.new(B, self.Hparams.n_mels*self.Hparams.reduction).zero_()
current_attn_rnn_h = encoded.data.new(1, B, self.Hparams.cbhg_gru_hidden_dim*2).zero_()
current_dec_rnn_h = encoded.data.new(2, B, self.Hparams.cbhg_gru_hidden_dim*2).zero_()
elif (t > 0):
# current decoder input
if (self.teacher_forcing == True and ground_truth != None):
current_dec_in = decoder_in[t-1]
else:
current_dec_in = decoder_out_list[-1].squeeze(1)
dec_out = self.dec_prenet(current_dec_in)
dec_out, current_attn_rnn_h = self.attention_rnn(dec_out, current_attn_rnn_h)
current_context, align = self.attention(dec_out, encoded) # 2021.08.03: attention input had changed "current_attn_rnn_h" to "dec_out"
attention_result = self.attention_wrapper(current_context, dec_out)
dec_out = self.pre_decoder_rnn(attention_result)
sub_dec_out, current_dec_rnn_h = self.decoder_rnn(dec_out, current_dec_rnn_h)
short_cut = self.residual(sub_dec_out)
dec_out = dec_out + short_cut # residual connection
dec_out = self.proj_to_mel(dec_out)
decoder_out_list.append(dec_out)
align_list.append(align)
t += 1
if (t >= T):
break
assert len(decoder_out_list) == T
mels = torch.cat(decoder_out_list, dim=1).contiguous()
aligns = torch.cat(align_list, dim=2)
return mels, aligns
while 문을 보면
가장 밑 부분에 if (t >= T): 에 해당하는 부분에서
종료하게끔 설계되어있습니다.
(T 값을 결정하는 방법은 코드블럭 상단에 있으므로 참고 바랍니다.)
먼저 t = 0 일 때 init 값들을 초기화합니다.
그리고 init 값들은
바로 self.dec_prenet()으로 입력되며 한 번의 루프를 마치고
dec_out은 decoder_out_list에,
align은 align_list에 담기게 됩니다.
여기서부터가 중요한 부분입니다.
t > 0 일 때
Teacher Forcing을 사용한다면
teacher_forcing=True 값으로 지정되어있어야하고,
ground_truth 값으로 mels을 입력해주어야합니다.
그리고 current_dec_in 값은
이 전 단계(t-1)의 손질된 ground_truth의 값으로 변경되며,
self.dec_prenet()으로 입력되고
t = 0 일 때와 같은 루프를 마치게 됩니다.
Teacher Forcing을 사용하지 않는다면
if (self.teacher_forcing == True and ground_truth != None):
조건만 만족하지 않으면 됩니다.
그리고 current_dec_in 값은
이 전 단계(t-1)의 dec_out 값이 담긴
decoder_out_list[-1] 값으로 변경되며
self.dec_prenet()으로 입력되고
t = 0 일 때와 같은 루프를 마치게 됩니다.
아래의 코드 블럭은 teacher_forcing=True로 지정하고
ground_truth를 mels로 입력하게한 출력 결과입니다.
dataset = KSSDataset(hparams)
dataloader = torch.utils.data.DataLoader(dataset,
batch_size=4,
shuffle=True,
collate_fn=collate_fn)
encoder = Encoder(hparams, use_decoder=False, use_post=False)
decoder = Decoder(hparams, use_decoder=True, teacher_forcing=True)
for step, values in enumerate(dataloader):
texts, mels, _, mel_lengths = values
encoded = encoder(texts)
mels, aligns = decoder(encoded, mel_lengths, mels)
print('Encoder result: {} \nDecoder result: {} \nAlignments result: {} \n'.format(
encoded.size(), mels.size(), aligns.size()))
if step == 4:
break
####
Encoder result: torch.Size([4, 49, 256])
Decoder result: torch.Size([4, 75, 400])
Alignments result: torch.Size([4, 49, 75])
Encoder result: torch.Size([4, 51, 256])
Decoder result: torch.Size([4, 57, 400])
Alignments result: torch.Size([4, 51, 57])
Encoder result: torch.Size([4, 43, 256])
Decoder result: torch.Size([4, 70, 400])
Alignments result: torch.Size([4, 43, 70])
Encoder result: torch.Size([4, 47, 256])
Decoder result: torch.Size([4, 66, 400])
Alignments result: torch.Size([4, 47, 66])
Encoder result: torch.Size([4, 44, 256])
Decoder result: torch.Size([4, 56, 400])
Alignments result: torch.Size([4, 44, 56])decoder = Decoder(hparams, use_decoder=True, teacher_forcing=True)
print(decoder)
####
Decoder(
(dec_prenet): PreNet(
(prenet): Sequential(
(0): CustomLinear(
(linear): Linear(in_features=400, out_features=256, bias=True)
(activation): ReLU()
(dropout): Dropout(p=0.5, inplace=False)
)
(1): CustomLinear(
(linear): Linear(in_features=256, out_features=128, bias=True)
(activation): ReLU()
(dropout): Dropout(p=0.5, inplace=False)
)
)
)
(attention_rnn): AttentionRNN(
(attention_rnn): GRU(128, 256, batch_first=True)
)
(attention): BahdanauAttention()
(attention_wrapper): AttentionWrapper()
(pre_decoder_rnn): CustomLinear(
(linear): Linear(in_features=512, out_features=256, bias=True)
)
(residual): Identity()
(decoder_rnn): DecoderRNN(
(decoder_rnn): GRU(256, 256, num_layers=2, batch_first=True)
)
(proj_to_mel): CustomLinear(
(linear): Linear(in_features=256, out_features=400, bias=True)
)
)
aligns의 shape을 보면
(B, Encoder_T, Decoder_T) 이런식으로 되어있습니다.
Encoder_T는 Sequence 길이에 해당하는 부분이고
Decoder_T는 방금 정의한 T(from mel_lengths)입니다.
각각의 길이는 나중에
alignment 그래프를 그릴 때 기준이 됩니다.

Post CBHG & Linear-Scaling Layer
Post CBHG는 Encoder CBHG를 구현할 때 관련된 언급을 했으므로
간략하게 설명하고 넘어가겠습니다.
Decoder에서 출력된 Predicted Mels가 Post CBHG로 입력될 때,
바로 입력되기보다는 shape을 변경해야합니다.
위의 코드 블럭에서 출력을 보면 알 수 있듯이,
현재의 shape은 (B, -1, n_mels*reduction)와 같습니다.
우리가 원하는 shape은 (B, -1, n_mels) 이므로
Predicted Mels의 shape을 변경해서 Post CBHG에 입력합니다.
마지막으로 linear_scaling 이라는 변수에 지정된 CustomLinear Layer가 있는데,
이는 Predicted Mels를 Predicted Specs로 Up-Scaling 하는 과정이라고 보면 됩니다.
Up-Scaling 까지 고려한 출력은 아래와 같습니다.
dataset = KSSDataset(hparams)
dataloader = torch.utils.data.DataLoader(dataset,
batch_size=4,
shuffle=True,
collate_fn=collate_fn)
encoder = Encoder(hparams, use_decoder=False, use_post=False)
decoder = Decoder(hparams, use_decoder=True, teacher_forcing=True)
post_cbhg = CBHG(hparams, use_post=True)
linear_scaling = CustomLinear(hparams.n_mels*2, hparams.n_specs)
for step, values in enumerate(dataloader):
texts, mels, _, mel_lengths = values
mel_length = torch.max(mel_lengths)
encoded = encoder(texts)
pred_mels, aligns = decoder(encoded, mel_length, mels)
post_cbhg_result = post_cbhg(mels.view(texts.size(0), -1, hparams.n_mels))
pred_specs = linear_scaling(post_cbhg_result)
print("Encoder result: {} \nMax Batch Mel Length: {}\
\nDecoder result: {} \nAlignments result: {}\
\nPost CBHG result: {} \nFinal result: {} \n".format(
encoded.size(), mel_length,
pred_mels.size(), aligns.size(),
post_cbhg_result.size(), pred_specs.size()))
if step == 4:
break
####
Encoder result: torch.Size([4, 43, 256])
Max Batch Mel Length: 695
Decoder result: torch.Size([4, 139, 400])
Alignments result: torch.Size([4, 43, 139])
Post CBHG result: torch.Size([4, 695, 160])
Final result: torch.Size([4, 695, 513])
Encoder result: torch.Size([4, 42, 256])
Max Batch Mel Length: 580
Decoder result: torch.Size([4, 116, 400])
Alignments result: torch.Size([4, 42, 116])
Post CBHG result: torch.Size([4, 580, 160])
Final result: torch.Size([4, 580, 513])
Encoder result: torch.Size([4, 58, 256])
Max Batch Mel Length: 860
Decoder result: torch.Size([4, 172, 400])
Alignments result: torch.Size([4, 58, 172])
Post CBHG result: torch.Size([4, 860, 160])
Final result: torch.Size([4, 860, 513])
Encoder result: torch.Size([4, 46, 256])
Max Batch Mel Length: 620
Decoder result: torch.Size([4, 124, 400])
Alignments result: torch.Size([4, 46, 124])
Post CBHG result: torch.Size([4, 620, 160])
Final result: torch.Size([4, 620, 513])
Encoder result: torch.Size([4, 44, 256])
Max Batch Mel Length: 610
Decoder result: torch.Size([4, 122, 400])
Alignments result: torch.Size([4, 44, 122])
Post CBHG result: torch.Size([4, 610, 160])
Final result: torch.Size([4, 610, 513])
아래의 코드 블럭을 실행하면 다음과 같은 Alignment Graph가 생성됩니다.
pred_mels, aligns = decoder(encoded, mel_lengths, mels)
plt.imshow(aligns[-1].detach().cpu().numpy())
Tacotron
Tacotron 설계의 마지막 부분입니다.
그동안 구현한걸 모두 넣으면 됩니다.
조금 차별을 둔 점이 있다면,
Teacher Forcing의 여부를 model을 선언할 때
지정할 수 있게끔 한 부분입니다.
사실 __init__ 부분에 두지 않고 Decoder부분에 True 값으로
고정하고 해도 무방할 듯 합니다.
Teacher Forcing을 사용하고 싶지 않다면,
아래 코드블럭과 같이 model을 선언하고 사용하면 됩니다.
model = Tacotron(hparams, teacher_forcing=False)
논문에서는 Mel과 Spec의 Loss를 L1을 이용했다고 했으므로
torch.nn.L1Loss() 함수를 이용해서
다른 값들과 함께 Loss도 출력해보겠습니다.
class Tacotron(torch.nn.Module):
def __init__(self, Hparams, teacher_forcing=False):
super(Tacotron, self).__init__()
self.Hparams = Hparams
self.teacher_forcing = teacher_forcing
self.encoder = Encoder(self.Hparams, use_decoder=False, use_post=False)
self.decoder = Decoder(self.Hparams, use_decoder=True, teacher_forcing=self.teacher_forcing)
self.post_cbhg = CBHG(self.Hparams, use_post=True)
self.linear_scaling = CustomLinear(in_features=self.Hparams.n_mels*2,
out_features=self.Hparams.n_specs,
activation=None,
dropout=None)
def forward(self, texts, mel_lengths, mels):
B = texts.size(0)
encoded = self.encoder(texts)
mels, aligns = self.decoder(encoded, mel_lengths, mels)
mels = mels.view(B, -1, self.Hparams.n_mels)
specs = self.post_cbhg(mels)
specs = self.linear_scaling(specs)
return mels, specs, alignsdataset = KSSDataset(hparams)
dataloader = torch.utils.data.DataLoader(dataset,
batch_size=4,
shuffle=True,
collate_fn=collate_fn)
model = Tacotron(hparams, teacher_forcing=True)
criterion = torch.nn.L1Loss()
for step, values in enumerate(dataloader):
texts, mels, specs, mel_lengths = values
pred_mels, pred_specs, aligns = model(texts, mel_lengths, mels)
mel_loss = criterion(pred_mels, mels)
spec_loss = criterion(pred_specs, specs)
print("Original Mels: {} \nPredicted Mels result: {}\
\nOriginal Specs {} \nPredicted Specs result: {} \nAlignments result: {}\
\nMel Loss: {} \nSpec Loss: {} \n".format(
mels.size(), pred_mels.size(),
specs.size(), pred_specs.size(), aligns.size(),
mel_loss, spec_loss))
if step == 4:
break
####
Original Mels: torch.Size([4, 345, 80])
Predicted Mels result: torch.Size([4, 345, 80])
Original Specs torch.Size([4, 345, 513])
Predicted Specs result: torch.Size([4, 345, 513])
Alignments result: torch.Size([4, 52, 69])
Mel Loss: 56.22419357299805
Spec Loss: 41.58668899536133
Original Mels: torch.Size([4, 350, 80])
Predicted Mels result: torch.Size([4, 350, 80])
Original Specs torch.Size([4, 350, 513])
Predicted Specs result: torch.Size([4, 350, 513])
Alignments result: torch.Size([4, 50, 70])
Mel Loss: 41.0747184753418
Spec Loss: 30.709251403808594
Original Mels: torch.Size([4, 335, 80])
Predicted Mels result: torch.Size([4, 335, 80])
Original Specs torch.Size([4, 335, 513])
Predicted Specs result: torch.Size([4, 335, 513])
Alignments result: torch.Size([4, 48, 67])
Mel Loss: 50.32085037231445
Spec Loss: 37.164085388183594
Original Mels: torch.Size([4, 360, 80])
Predicted Mels result: torch.Size([4, 360, 80])
Original Specs torch.Size([4, 360, 513])
Predicted Specs result: torch.Size([4, 360, 513])
Alignments result: torch.Size([4, 53, 72])
Mel Loss: 52.56007385253906
Spec Loss: 38.50770568847656
Original Mels: torch.Size([4, 355, 80])
Predicted Mels result: torch.Size([4, 355, 80])
Original Specs torch.Size([4, 355, 513])
Predicted Specs result: torch.Size([4, 355, 513])
Alignments result: torch.Size([4, 54, 71])
Mel Loss: 56.1495246887207
Spec Loss: 41.48576354980469
Tacotron의 전체 모델 구조는 아래와 같습니다.
model = Tacotron(hparams, teacher_forcing=True)
print(model)
####
Tacotron(
(encoder): Encoder(
(encoder): Sequential(
(0): Embedding(
(embedding_layer): Sequential(
(0): Embedding(74, 256)
)
)
(1): PreNet(
(prenet): Sequential(
(0): CustomLinear(
(linear): Linear(in_features=256, out_features=256, bias=True)
(activation): ReLU()
(dropout): Dropout(p=0.5, inplace=False)
)
(1): CustomLinear(
(linear): Linear(in_features=256, out_features=128, bias=True)
(activation): ReLU()
(dropout): Dropout(p=0.5, inplace=False)
)
)
)
(2): CBHG(
(residual): Sequential(
(0): Identity()
)
(conv1d_bank): ModuleList(
(0): BatchNormConv1D(
(conv1d): Conv1d(128, 128, kernel_size=(1,), stride=(1,), padding=(2,))
(batchnorm1d): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activation): ReLU()
)
(1): BatchNormConv1D(
(conv1d): Conv1d(128, 128, kernel_size=(2,), stride=(1,), padding=(2,))
(batchnorm1d): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activation): ReLU()
)
(2): BatchNormConv1D(
(conv1d): Conv1d(128, 128, kernel_size=(3,), stride=(1,), padding=(2,))
(batchnorm1d): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activation): ReLU()
)
(3): BatchNormConv1D(
(conv1d): Conv1d(128, 128, kernel_size=(4,), stride=(1,), padding=(2,))
(batchnorm1d): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activation): ReLU()
)
)
(conv1d_proj): Sequential(
(0): MaxPool1d(kernel_size=2, stride=1, padding=1, dilation=2, ceil_mode=False)
(1): BatchNormConv1D(
(conv1d): Conv1d(512, 512, kernel_size=(3,), stride=(1,), padding=(1,))
(batchnorm1d): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activation): ReLU()
)
(2): BatchNormConv1D(
(conv1d): Conv1d(512, 128, kernel_size=(3,), stride=(1,), padding=(1,))
(batchnorm1d): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(pre_highway): Sequential(
(0): CustomLinear(
(linear): Linear(in_features=128, out_features=128, bias=True)
)
)
(highway): Sequential(
(0): Highway(
(H): CustomLinear(
(linear): Linear(in_features=128, out_features=128, bias=True)
(activation): ReLU()
)
(T): CustomLinear(
(linear): Linear(in_features=128, out_features=128, bias=True)
(activation): Sigmoid()
)
)
(1): Highway(
(H): CustomLinear(
(linear): Linear(in_features=128, out_features=128, bias=True)
(activation): ReLU()
)
(T): CustomLinear(
(linear): Linear(in_features=128, out_features=128, bias=True)
(activation): Sigmoid()
)
)
(2): Highway(
(H): CustomLinear(
(linear): Linear(in_features=128, out_features=128, bias=True)
(activation): ReLU()
)
(T): CustomLinear(
(linear): Linear(in_features=128, out_features=128, bias=True)
(activation): Sigmoid()
)
)
(3): Highway(
(H): CustomLinear(
(linear): Linear(in_features=128, out_features=128, bias=True)
(activation): ReLU()
)
(T): CustomLinear(
(linear): Linear(in_features=128, out_features=128, bias=True)
(activation): Sigmoid()
)
)
)
(gru): Sequential(
(0): GRU(128, 128, batch_first=True, bidirectional=True)
)
)
)
)
(decoder): Decoder(
(dec_prenet): PreNet(
(prenet): Sequential(
(0): CustomLinear(
(linear): Linear(in_features=400, out_features=256, bias=True)
(activation): ReLU()
(dropout): Dropout(p=0.5, inplace=False)
)
(1): CustomLinear(
(linear): Linear(in_features=256, out_features=128, bias=True)
(activation): ReLU()
(dropout): Dropout(p=0.5, inplace=False)
)
)
)
(attention_rnn): AttentionRNN(
(attention_rnn): GRU(128, 256, batch_first=True)
)
(attention): BahdanauAttention()
(attention_wrapper): AttentionWrapper()
(pre_decoder_rnn): CustomLinear(
(linear): Linear(in_features=512, out_features=256, bias=True)
)
(residual): Identity()
(decoder_rnn): DecoderRNN(
(decoder_rnn): GRU(256, 256, num_layers=2, batch_first=True)
)
(proj_to_mel): CustomLinear(
(linear): Linear(in_features=256, out_features=400, bias=True)
)
)
(post_cbhg): CBHG(
(residual): Sequential(
(0): Identity()
)
(conv1d_bank): ModuleList(
(0): BatchNormConv1D(
(conv1d): Conv1d(80, 80, kernel_size=(1,), stride=(1,), padding=(1,))
(batchnorm1d): BatchNorm1d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activation): ReLU()
)
(1): BatchNormConv1D(
(conv1d): Conv1d(80, 80, kernel_size=(2,), stride=(1,), padding=(1,))
(batchnorm1d): BatchNorm1d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activation): ReLU()
)
)
(conv1d_proj): Sequential(
(0): MaxPool1d(kernel_size=2, stride=1, padding=1, dilation=2, ceil_mode=False)
(1): BatchNormConv1D(
(conv1d): Conv1d(160, 1024, kernel_size=(3,), stride=(1,), padding=(1,))
(batchnorm1d): BatchNorm1d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activation): ReLU()
)
(2): BatchNormConv1D(
(conv1d): Conv1d(1024, 80, kernel_size=(3,), stride=(1,), padding=(1,))
(batchnorm1d): BatchNorm1d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(pre_highway): Sequential(
(0): CustomLinear(
(linear): Linear(in_features=80, out_features=128, bias=True)
)
)
(highway): Sequential(
(0): Highway(
(H): CustomLinear(
(linear): Linear(in_features=128, out_features=128, bias=True)
(activation): ReLU()
)
(T): CustomLinear(
(linear): Linear(in_features=128, out_features=128, bias=True)
(activation): Sigmoid()
)
)
(1): Highway(
(H): CustomLinear(
(linear): Linear(in_features=128, out_features=128, bias=True)
(activation): ReLU()
)
(T): CustomLinear(
(linear): Linear(in_features=128, out_features=128, bias=True)
(activation): Sigmoid()
)
)
(2): Highway(
(H): CustomLinear(
(linear): Linear(in_features=128, out_features=128, bias=True)
(activation): ReLU()
)
(T): CustomLinear(
(linear): Linear(in_features=128, out_features=128, bias=True)
(activation): Sigmoid()
)
)
(3): Highway(
(H): CustomLinear(
(linear): Linear(in_features=128, out_features=128, bias=True)
(activation): ReLU()
)
(T): CustomLinear(
(linear): Linear(in_features=128, out_features=128, bias=True)
(activation): Sigmoid()
)
)
)
(gru): Sequential(
(0): GRU(128, 80, batch_first=True, bidirectional=True)
)
)
(linear_scaling): CustomLinear(
(linear): Linear(in_features=160, out_features=513, bias=True)
)
)
설명이 난해한 부분이 있어서
두고두고 수정해야겠네요.
어쨌든 Tacotron 구현은 끝났으니
다음 포스팅에서는 전체 데이터에 대한 전처리와 Griffin-Lim,
train step과 iteration 부분을 다뤄보도록 하겠습니다.
긴 글 읽어주셔서 감사합니다.
제가 작성한 포스트에 오류가 있다면 언제든지 댓글 부탁드립니다 :)