-
Tacotron 무지성 구현 - 1/NTacotron 1 2021. 7. 27. 00:12
저는 전공자가 아닙니다.
현업에서 사용되는 알고리즘과 전처리 방법 등은 이해하기 어려울 정도로 복잡하기 때문에
최대한 가볍게 시작해서 이해하고 기록하고자 시작했습니다.
저는 음악, 소리에 대해서 잘 모르기도 하고, 어디서 주워들은 걸 토대로 구글링 해서
논문을 보며 혼자 공부하고 있습니다.
따라서 제가 작성한 포스팅은 정확하지 않을 수 있습니다.
코드에서 틀린 부분이나 오개념 지적은 언제든지 환영입니다 :)
Tacotron 논문 https://arxiv.org/abs/1703.10135
Tacotron: Towards End-to-End Speech Synthesis
A text-to-speech synthesis system typically consists of multiple stages, such as a text analysis frontend, an acoustic model and an audio synthesis module. Building these components often requires extensive domain expertise and may contain brittle design c
arxiv.org
chldkato님과 r9y9님의 깃허브에서 많은 참고를 했습니다.
무지성 구현 시작합니다 :)
데이터 구성 (KSS)
KSS 데이터셋 URL : https://www.kaggle.com/bryanpark/korean-single-speaker-speech-dataset?select=kss
Korean Single Speaker Speech Dataset
KSS Dataset: Korean Single Speaker Speech Dataset
www.kaggle.com
데이터셋을 다운로드하고 압축해제를 하게 되면,
'kss/' 경로 아래에 '1', '2', '3', '4'와 같이 서브 폴더와 함께 ' transcript.v.1.4'라는 이름으로 스크립트가 있습니다.

음원파일 경로 | 한글 문장 1 | 한글 문장 2 | 한글 문장 3 | 영어문장 순서대로 되어있습니다.
음원파일 경로 부분을 보면 1/1_0000.wav로 되어있는 걸 볼 수 있는데,
이는 서브폴더/음원파일명 으로 되어있다는 의미입니다.

Tacotron 모델 구조
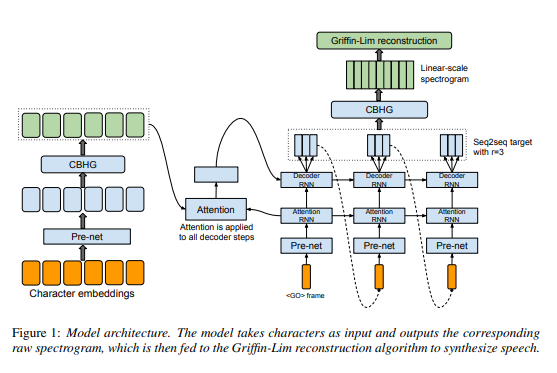
타코트론은 Attention 기반 Sequence to Sequence 구조입니다. Attention 부분을 기준으로 왼쪽 부분은 Encoder에 해당하고, 오른쪽 부분에서 <GO> frame 부분부터 CBHG 아래까지가 Decoder에 해당합니다. Encoder에 첫 입력값으로 Text를 입력한 뒤 Decoder의 Attention RNN 출력값과 함께 Attention을 거쳐서 Decoder의 Pre-net, Attention RNN을 통과한 값과 Concatenate되어 Decoder RNN의 입력값으로 사용됩니다.
음원파일 경로 및 문자열 JSON 저장
일반적으로 전처리하거나 또는 학습을 위해 음원과 문장 데이터를 불러올 때, 음원경로-문장과 같이 쌍을 이룬 데이터를 구성해두면 편리하다고 합니다. 따라서 아래와 같이 간단하게 JSON파일 형식으로 저장하고 출력해봅니다.
import os, glob, json data_path = os.path.join('data') def get_pairs_from_source(hparams, save=True): print("Getting pairs from metadata") source_dir = os.path.join(hparams.data_dir, hparams.speaker) if not os.path.isdir(source_dir): print("There are not exist data directories. Please check directory which is %s" % source_dir) source_file = glob.glob(os.path.join(source_dir, '*.txt'))[0] # path|text|text|text|digit|text pairs = {} with open(source_file, 'r', encoding='utf-8') as f: lines = f.readlines() # 읽어오기 metadata = [line.strip('\n') for line in lines] # 개행문자 제거 for line in metadata: audio_path = line.split('|')[0] # audio path if '/' in audio_path: audio_path = audio_path.split('/') audio_path = os.path.join(audio_path[0], audio_path[1]) text = line.split('|')[1] # text pairs[os.path.join(source_dir, audio_path)] = text # save as dictionary if save==True: with open(os.path.join(hparams.data_dir, 'alignments.json'), 'w', encoding='UTF-8') as json_file: json.dump(pairs, json_file, ensure_ascii=False, indent=4, sort_keys=False) return pairs alignments = get_pairs_from_source(data_path, save=True) for idx, pairs in enumerate(alignments.items()): print(pairs[0], pairs[1]) if idx == 4: break print('\n', len(alignments)) 1/1_0000.wav 그는 괜찮은 척하려고 애쓰는 것 같았다. 1/1_0001.wav 그녀의 사랑을 얻기 위해 애썼지만 헛수고였다. 1/1_0002.wav 용돈을 아껴 써라. 1/1_0003.wav 그는 아내를 많이 아낀다. 1/1_0004.wav 그 애 전화번호 알아? 128541. os, glob 모듈 임포트
2. 'data' 폴더 경로 아래에 'kss' 데이터가 포함된 폴더 위치
3. 데이터를 불러오는 별도 함수 작성
4. metadata로부터 alignment data 생성
5. alignment data 출력
오디오 데이터 전처리
Python 기반 음성 신호 관련 처리 기법은 위 YouTube 링크 영상으로 공부했습니다. 영상에서는 기본적으로 librosa 라이브러리를 사용하지만, 저는 하나의 라이브러리를 사용하는 것을 좋아하기 때문에 torchaudio를 사용했습니다. librosa 라이브러리를 사용하셔도 무방합니다. 음원 데이터 전처리에 사용될 인자들을 정리합니다.
클래스로 만든다면 편리하게 인자를 불러올 수 있습니다.
예를 들어 아래와 같이 클래스로 만들었을 때 다음과 같이 데이터를 불러올 수 있습니다.
n_fft = Hparams.n_fft
현재 지정한 인자들은 음원 데이터 전처리에 필요한 인자들만 입력했습니다.
앞으로 데이터 전처리나 모델 구성 및 학습에 사용될 인자들은 해당 클래스에 모두 넣도록 하겠습니다.
class Hparams(): # speaker name speaker = 'KSS' # Audio Pre-processing origin_sample_rate = 44100 sample_rate = 22050 n_fft = 1024 hop_length = 256 win_length = 1024 n_mels = 80 reduction = 5 n_specs = n_fft // 2 + 1 fmin = 0 fmax = sample_rate // 2 min_level_db = -100 ref_level_db = 20hyper parameter 값들은 keithito와 chldkato님이 구현한 데이터를 참고했습니다.
각 인자들의 값 의미하는 것은 다음 포스팅 시 열심히 구글링 해서 올릴 수 있도록 하겠습니다.
음원 데이터를 전처리할 때 디노이징과 관련된 부분은
아직까지 알고리즘으로 처리할 수 있는 것은 한계가 있다고 합니다.
keithito, chldkato님과 같이 hyper parameter에서 볼 수 있는
preemphasis(Pre-emphasis) 인자는 노이즈와 관련된 인자로,
Pre-emphasis 기법 자체가 파형을 송신할 때 고주파수 대역(1kHz~16kHz)에 해당하는 부분을 강조하여
후에 노이즈를 제거하는 기법이기 때문에,
비교적 노이즈가 많이 발생하는 부분인 고주파수 대역을 굳이 강조할 필요성이 없을 것 같아서
preemphasis 인자를 제외했습니다.
별도의 모듈을 구현하는 것보다 특정 시퀀스를 이용하여
손수 전처리를 하는 방법이 아직까지는 가장 좋은 방법인 것 같습니다.
그래도 스튜디오에서 녹음된 고품질의 데이터가 아닌 유튜브와 같은 저품질의 데이터를 기반으로
모델을 구현하는 경우가 종종 있기 때문에 시퀀스를 이용하는 것에도 한계가 있으므로,
Equalizer, Fade-in Fade-out과 같은 기법을 구현하여
100Hz 이하의 극저주파 대역을 지우고 앞 뒤를 매끄럽게 하는 방법도 좋은 방법입니다.
요즘에는 Pre-emphasis 기법보다는 CMN(Cepstral Mean Normalization) 기법을 사용해
노이즈와 같은 불필요성 데이터를 처리한다고 합니다.
CMN과 관련된 부분을 자세하게 알고 계신 분이 있으시다면 알려주시면 감사하겠습니다 :)
import torch, torchaudio class Hparams(): origin_sample_rate = 22050 sample_rate = 22050 n_fft = 1024 hop_length = 256 win_length = 1024 n_mels = 80 min_level_db = -80 ref_level_db = 0 class Spectrogram(torch.nn.Module): def __init__(self, Hparams): super(Spectrogram, self).__init__() self.Hparams = Hparams self.resampler = torchaudio.transforms.Resample(orig_freq=self.Hparams.origin_sample_rate, new_freq=self.Hparams.sample_rate) self.mel_filter = torchaudio.transforms.MelScale(n_mels=self.Hparams.n_mels, sample_rate=self.Hparams.sample_rate) def forward(self, audio, mel_return=True): if audio.size(0) != 1: # if stereo audio = torch.mean(audio, dim=0).unsqueeze(0) # to mono audio = self.resampler(audio) stft = torch.stft(input=audio, n_fft=self.Hparams.n_fft, hop_length=self.Hparams.hop_length, win_length=self.Hparams.win_length, return_complex = True) D = torch.abs(stft) min_level = torch.exp(self.Hparams.min_level_db / 20 * torch.log(torch.Tensor([10]))) spec = 20 * torch.log(torch.maximum(min_level, D)) - self.Hparams.ref_level_db spec = spec.permute(0,2,1) # (1, t_seq, spec_dim) if mel_return: filtered_D = self.mel_filter(D) mel = 20 * torch.log(torch.maximum(min_level, filtered_D)) - self.Hparams.ref_level_db mel = mel.permute(0,2,1) # (1, t_seq, n_mels) else: mel = None return spec, mel hparams = Hparams() spectrogram = Spectrogram(hparams) for idx, (path, _) in enumerate(alignments.items()): audio, _ = torchaudio.load(path) # audio, sample_rate spec, mel = spectrogram(audio, mel_return=True) print(spec.size(), mel.size()) if idx==4: break torch.Size([1, 608, 513]) torch.Size([1, 608, 80]) torch.Size([1, 685, 513]) torch.Size([1, 685, 80]) torch.Size([1, 304, 513]) torch.Size([1, 304, 80]) torch.Size([1, 398, 513]) torch.Size([1, 398, 80]) torch.Size([1, 230, 513]) torch.Size([1, 230, 80])torchaudio는 stft method와 별도의 mel-filter를 제공합니다.
전처리 클래스를 layer 모듈처럼 구현했는데, 메서드처럼 구현해도 좋을 듯 합니다.
torchaudio.transforms.Spectrogram과 torchaudio.transforms.MelSpectrogram을 이용하여
linear와 mel을 별도로 구할 수 있지만,
전처리되는 순서를 알고 싶어서 STFT -> ABS -> Clipping처럼 보편적인 순서대로 작성했습니다.
아래와 같이 필요한 인자를 지정한 뒤에 다음과 같이 mel-filter를 객체로 선언하고
STFT 처리된 audio를 mel-filter 객체에 입력 값으로 넣으면 Scaling 된 mel을 얻을 수 있습니다.
mel_filter = torchaudio.transforms.MelScale(n_mels, sample_rate) filtered_D = mel_filter(torch.abs(torch.stft(audio, **kwargs)))여기까지가 가장 기본적인 오디오 신호처리 부분입니다.
오디오 전처리를 하기 위해서는 spectrogram(mel 포함) 형태로 변환해주어야 합니다.
모든 음원을 spectrogram과 mel-spectrogram으로 현재 진행한 부분까지만 변환해서
학습해도 상관없을 테지만, 좋은 모델이 나올 거라고는 생각하지 않습니다.
따라서 앞서 설명드렸던 것 중에서, 시퀀스를 이용하여 사전에 전처리하거나 다른 모듈을 구현하여
spectrogram과 mel-spectrogram에 적용하는 방법을 생각해야 합니다.
아래와 같은 부분도 간단하게 적용된 일련의 Clipping 전처리 기법입니다.
(Clipping 기법이라고 생각되는데, 아니라면 댓글 부탁드립니다.)
# spec min_level = torch.exp(min_level_db / 20 * torch.log(torch.Tensor([10]))) spec = 20 * torch.log(torch.maximum(min_level, D)) - ref_level_db # mel filtered_D = mel_filter(D) min_level = torch.exp(min_level_db / 20 * torch.log(torch.Tensor([10]))) mel = 20 * torch.log(torch.maximum(min_level, filtered_D)) - ref_level_db아 참고로, 오디오와 음원을 중복해서 써놓았는데 서로 같은 의미입니다.
뭔가 뜬 구름 잡듯이 전처리하듯 장황하게 써놓았는데,
제가 작성한 포스트에 오류가 있다면 언제든지 댓글 부탁드립니다 :)
'Tacotron 1' 카테고리의 다른 글
Tacotron 무지성 구현 - 6/N (0) 2021.08.02 Tacotron 무지성 구현 - 5/N (0) 2021.07.30 Tacotron 무지성 구현 - 4/N (0) 2021.07.29 Tacotron 무지성 구현 - 3/N (0) 2021.07.27 Tacotron 무지성 구현 - 2/N (0) 2021.07.27